Chapter 11 Very Brief Intro to Data in R
11.1 Why R again?
11.1.2 Ok, but why R?
- R is free and open source!
- R has a vibrant online community!
- R is very flexible and powerful — adaptable to nearly any task ( e.g., correlations, econometrics, spatial data analysis, machine learning, web scraping, data cleaning, website building, teaching.)
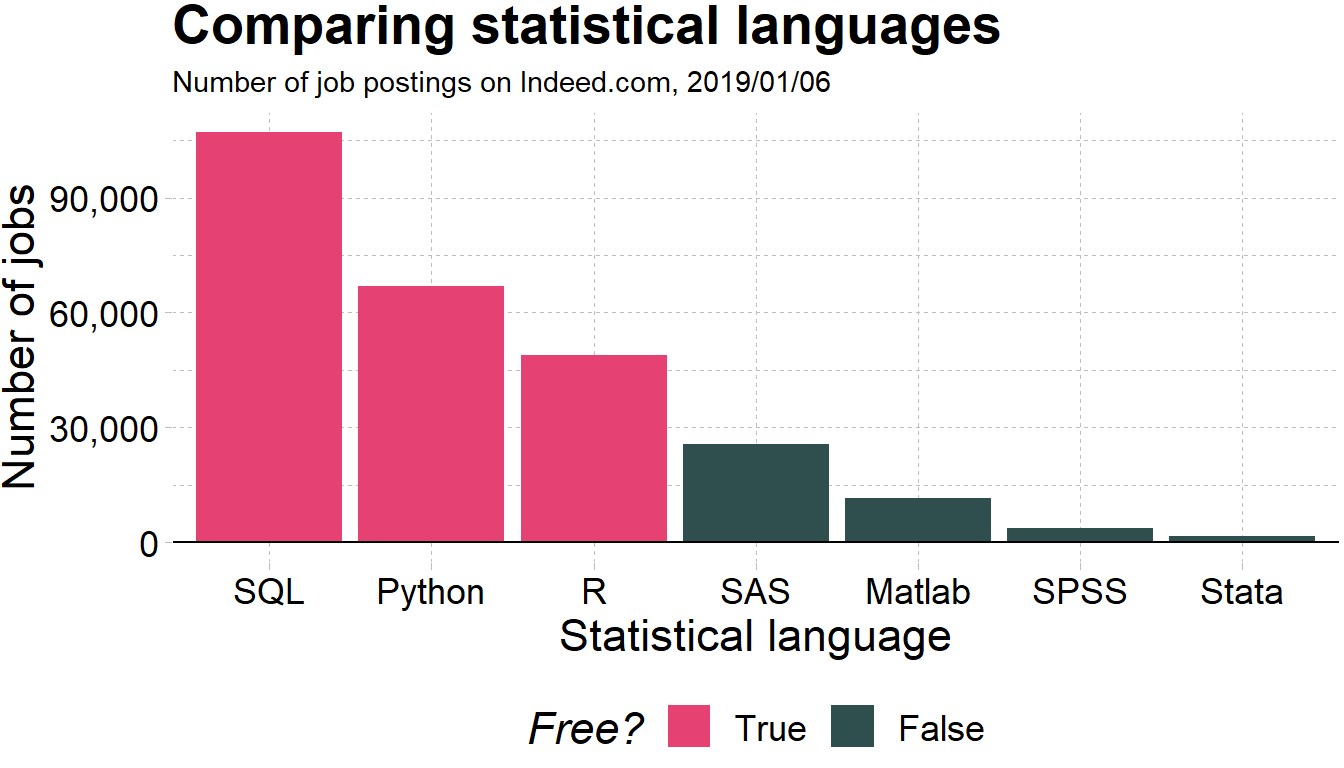
- Employers like R over alternatives
11.2 Key concepts before we start:
Before we can start exploring data in R, there are some key concepts to understand first:
- What are R, Posit Cloud and RStudio?
- How do I code in R?
- What are R packages?
We’ll introduce these concepts in upcoming Sections 11.2.1-11.6. Then we’ll introduce our first data set: data on the economic mobility for all neighborhoods across the US in the atlas dataset.
11.2.1 What are R and RStudio?
For much of this book, we will assume that you are using R via RStudio. First time users often confuse the two. At its simplest:
- R is like a car’s engine.
- RStudio is like a car’s dashboard.
| R: Engine | RStudio: Dashboard |
|---|---|
 |
 |
More precisely, R is a programming language that runs computations while RStudio is an integrated development environment (IDE) that provides an interface by adding many convenient features and tools. So just as having access to a speedometer, rearview mirrors, and a navigation system makes driving much easier, using RStudio’s interface makes using R much easier as well.
11.2.2 R and RStudio: In your computer or in the cloud? The benefit of Posit Cloud
To use R and RStudio, you can:
- install it in your computer (see the book) or …
- run it on someone else’s computer (the cloud!). We will do that, so you don’t have to worry about installations.
In this course I won’t require you to install R and RStudio in your own computer. Instead, we will use the cloud! In particular, the website that we will use to manage RStudio is called Posit Cloud.
You should have received an invitation for the course in your email. If you would still like to install R and RStudio in your own computer, please follow the instructions in Section 1.1.1 in this link. Of course, you are encouraged to experiment in your own machine as well. Notice, however, that you should carry out the assignments and projects in Posit Cloud.
Important!
Homework and projects should be carried in Posit Cloud (not your personal computer).
11.3 Let’s open R!
11.3.1 RStudio in Posit cloud
Let’s jump in! You should have received a link for you to access RStudio in the cloud through Posit Cloud. There is a monthly fee to use this service of $5. We will be using the service for the next 4 months, so you should be paying a total of $20 across these 4 months. Recall also that there is no required textbook for this class. Once the Fall semester finishes, it is your responsibility to cancel your subscription.
Once more: remember that all the code is running on someone’s computer. In this case, it is running on a computer owned by the folks at RStudio.
- Receive link with invitation
You should have received an email with a link inviting you to join Posit Cloud. Once you click on the link, you should land in a page like this:
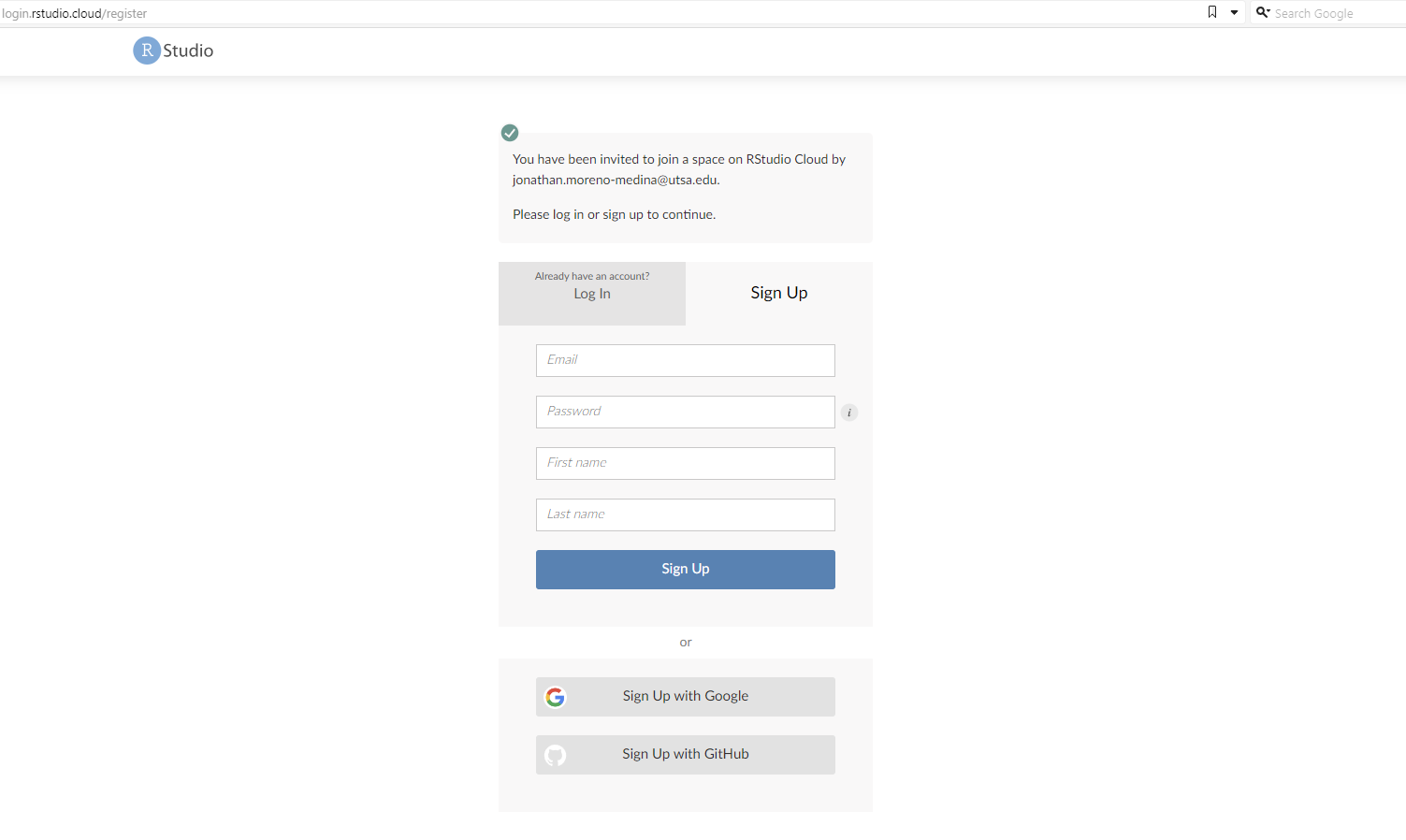
Then you should fill out the information for your account. Please use your utsa email account (the account you should have received the invitation to). Once you click on Sign Up, it will show this:
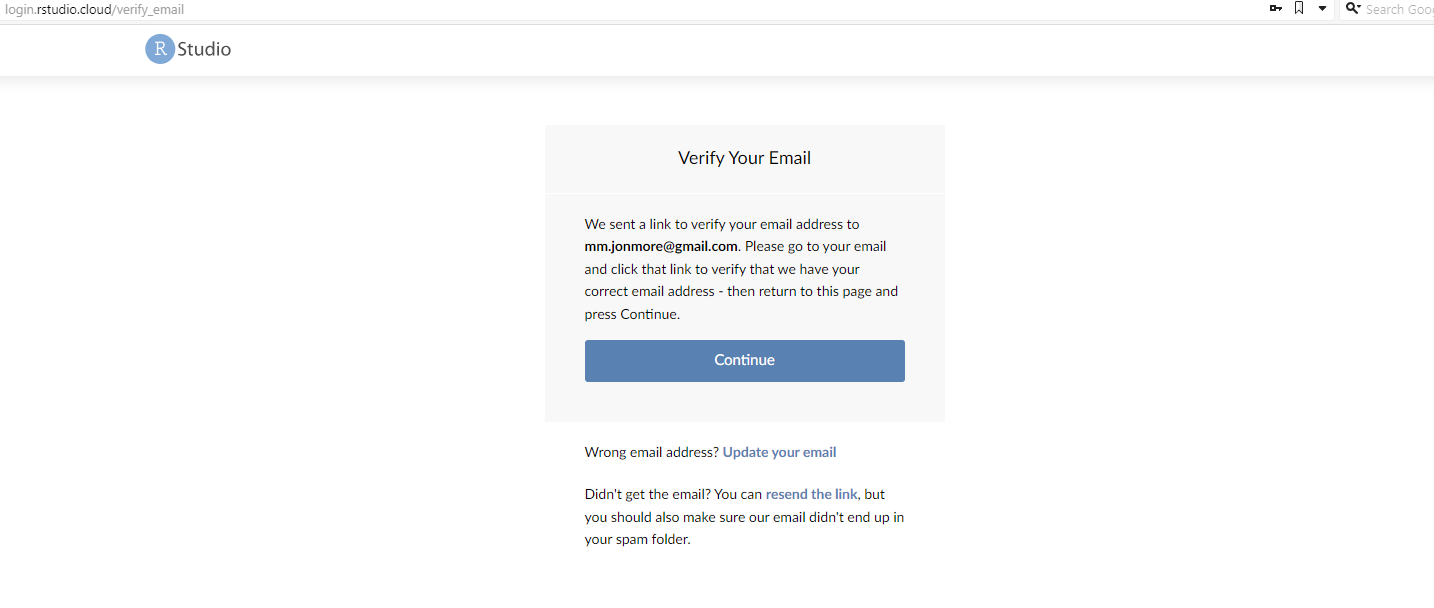
Then you need to go back to your email and verify it. Then log back in again!
- Inside Posit Cloud select ECO3523-Fall23
Once you have logged back in, you should land in the main page, which should look like this:
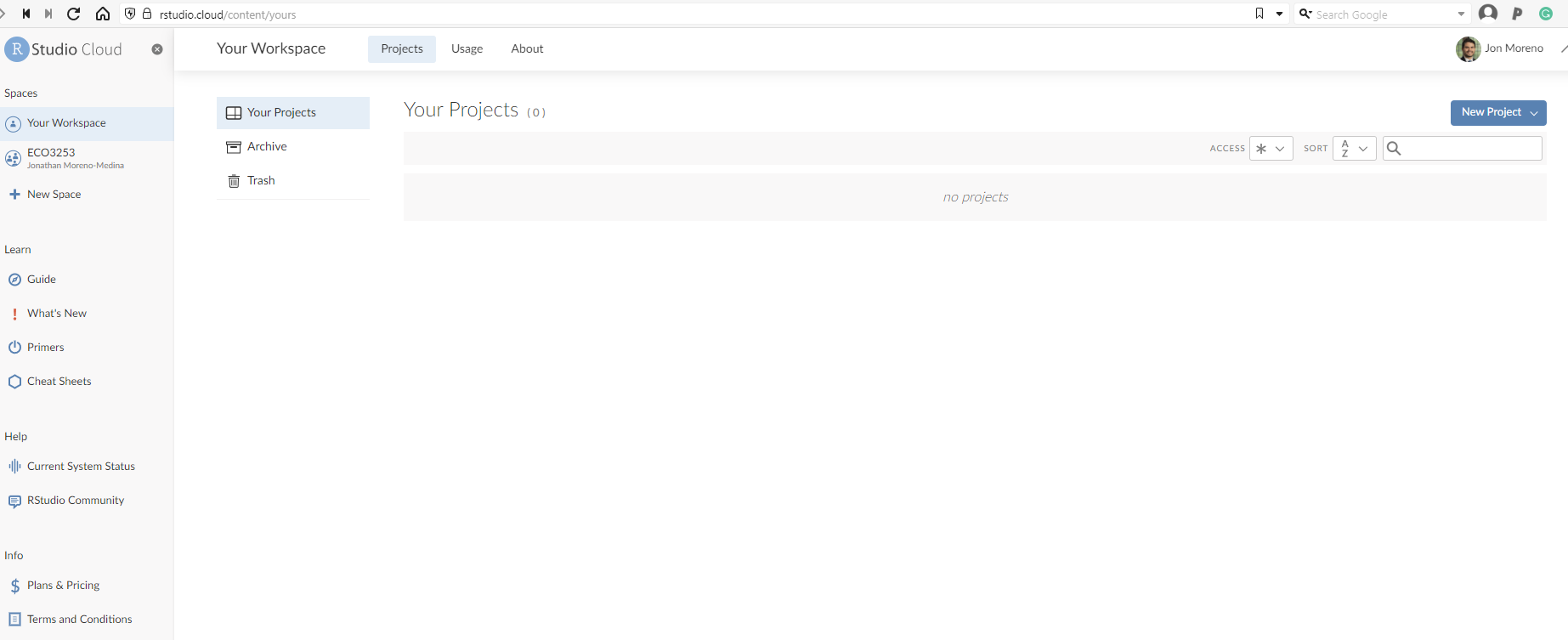
Click on the left where it says ECO3523-Fall23. That is where you will see all the material and projects for this class.
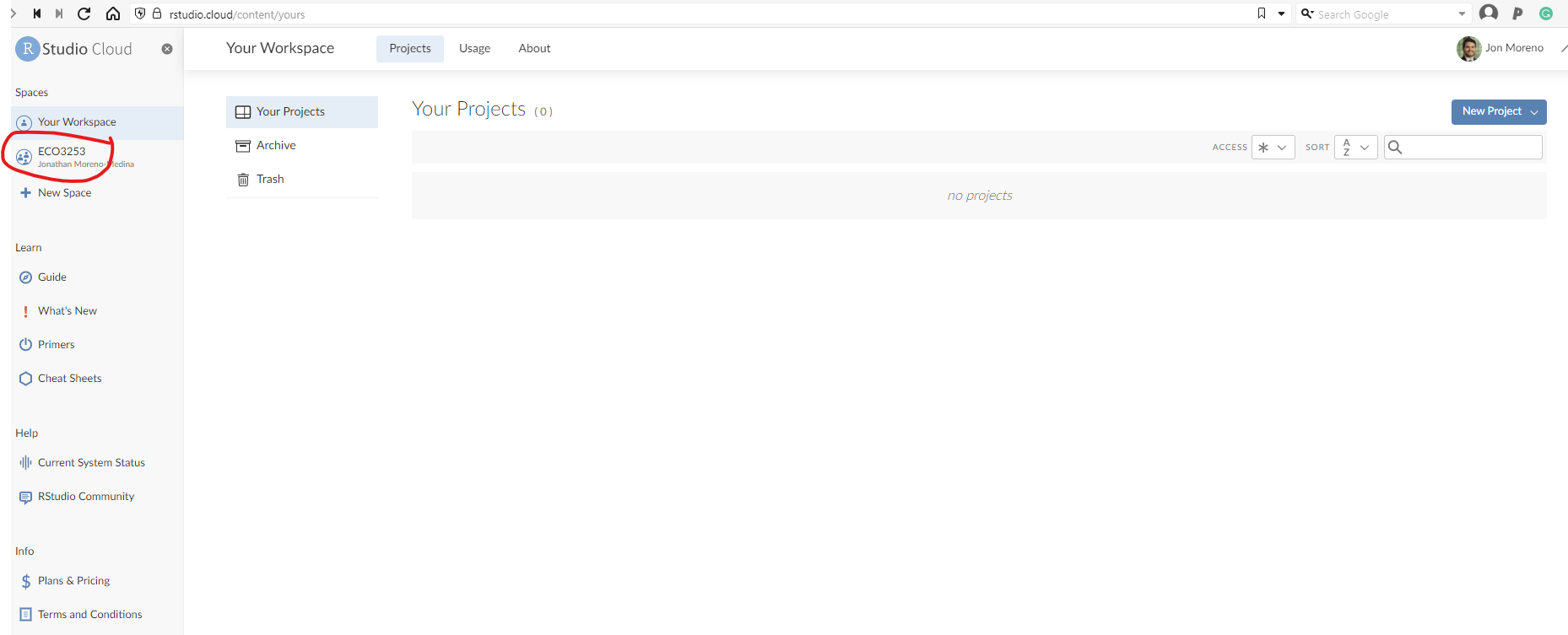
- Select the appropriate project you want to work on
Once you are in the ECO3523-Fall23 tab, you should see a list of individual projects we will work on throughout the semester. It should look something like this:
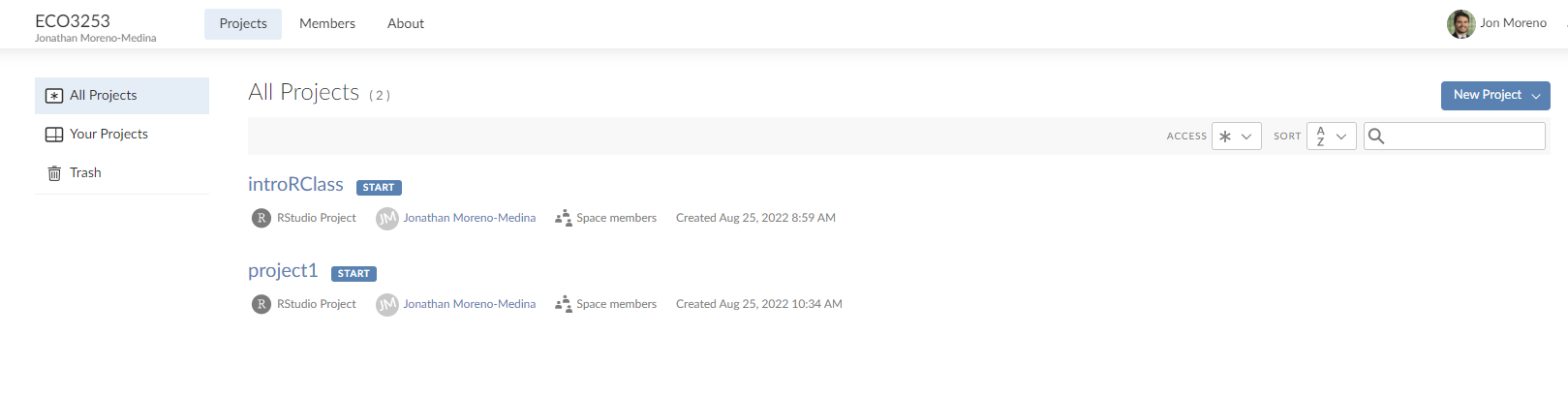
For our first class on R you will select the link that says introRClass. That is it! Now we are ready to get to work!
11.3.2 Using R via RStudio in Posit Cloud
Recall our car analogy from above. Much as we don’t drive a car by interacting directly with the engine but rather by interacting with elements on the car’s dashboard, we won’t be using R directly but rather we will use RStudio’s interface.
After you open Posit Cloud and follow the previous instructions, you should see a panel like the following:
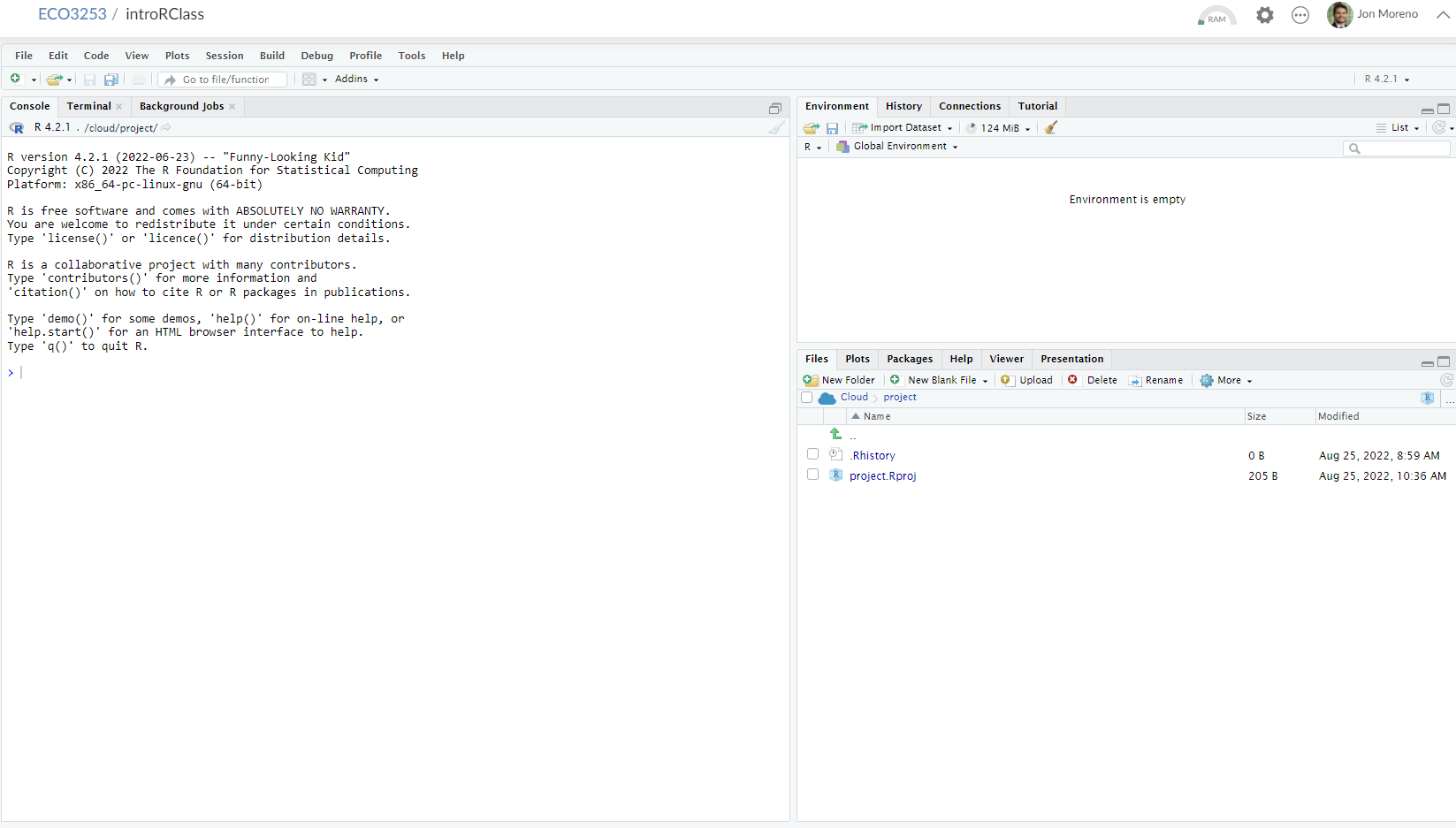
Note the three panes, which are three panels dividing the screen: The Console pane, the Files pane, and the Environment pane. Over the course of this chapter, you’ll come to learn what purpose each of these panes serve.
11.4 How do I code in R?
Now that you’re set up with Posit Cloud, you are probably asking yourself “OK. Now how do I use R?” The first thing to note as that unlike other statistical software programs like Excel, STATA, or SAS that provide point and click interfaces, R is an interpreted language, meaning you have to enter in R commands written in R code. In other words, you have to code/program in R. Note that we’ll use the terms “coding” and “programming” interchangeably in this book.
While it is not required to be a seasoned coder/computer programmer to use R, there is still a set of basic programming concepts that R users need to understand. Consequently, while this course is not a book on programming, you will still learn just enough of these basic programming concepts needed to explore and analyze data effectively.
11.4.1 Basic programming concepts and terminology
We now introduce some basic programming concepts and terminology. Instead of asking you to learn all these concepts and terminology right now, we’ll guide you so that you’ll “learn by doing.” Note that in this book we will always use a different font to distinguish regular text from computer_code. The best way to master these topics is, in our opinions, “learning by doing” and lots of repetition.
- Basics:
- Console: Where you enter in commands.
- Running code: The act of telling R to perform an action by giving it commands in the console.
- Objects: Where values are saved in R. In order to do useful and interesting things in R, we will want to assign a name to an object. For example we could do the following assignments:
x <- 44 - 20andthree <- 3. This would allow us to runx + threewhich would return27. - Data types: Integers, doubles/numerics, logicals, and characters.
- Vectors: A series of values. These are created using the
c()function, wherec()stands for “combine” or “concatenate.” For example:c(6, 11, 13, 31, 90, 92). - Factors: Categorical data are represented in R as factors.
- Data frames: Data frames are like rectangular spreadsheets: they are representations of datasets in R where the rows correspond to observations and the columns correspond to variables that describe the observations. We’ll cover data frames later in Section 11.7.1.
- Conditionals:
- Testing for equality in R using
==(and not=which is typically used for assignment). Ex:2 + 1 == 3compares2 + 1to3and is correct R code, while2 + 1 = 3will return an error. - Boolean algebra:
TRUE/FALSEstatements and mathematical operators such as<(less than),<=(less than or equal), and!=(not equal to). - Logical operators:
&representing “and” as well as|representing “or.” Ex:(2 + 1 == 3) & (2 + 1 == 4)returnsFALSEsince both clauses are notTRUE(only the first clause isTRUE). On the other hand,(2 + 1 == 3) | (2 + 1 == 4)returnsTRUEsince at least one of the two clauses isTRUE.
- Testing for equality in R using
- Functions, also called commands: Functions perform tasks in R. They take in inputs called arguments and return outputs. You can either manually specify a function’s arguments or use the function’s default values.
This list is by no means an exhaustive list of all the programming concepts and terminology needed to become a savvy R user; such a list would be so large it wouldn’t be very useful, especially for novices. Rather, we feel this is a minimally viable list of programming concepts and terminology you need to know before getting started. I’m confident you can learn the rest as you go. Remember that your mastery of all of these concepts and terminology will build as you practice more and more.1
11.5 In Class Exercise
Try running the following commands in the console. What do you see for each one?
2*3
2*pi
log(10)
exp(2)
sqrt(25)
3==3
3==4
3<=4
3!=4
x <- c(1,3,2,5)# this is called a 'vector'
x #what do you see?
x <- c(1,6,2)
x #now what do you see?
y <- c(1,4,3) # USE ARROW!
length(x)
length(y)
x+y
#write this
write this again11.5.1 Errors, warnings, and messages
Noticed the last thing that appeared in the console when you wrote write this again? It had scary red letters. It is an example of something that intimidates new R and RStudio users: how it reports errors, warnings, and messages. R reports errors, warnings, and messages in a glaring red font, which makes it seem like it is scolding you. However, seeing red text in the console is not always bad.
R will show red text in the console pane in three different situations:
- Errors: When the red text is a legitimate error, it will be prefaced with “Error in…” and try to explain what went wrong. Generally when there’s an error, the code will not run. For example, we’ll see in Subsection 11.6.3 if you see
Error in ggplot(...) : could not find function "ggplot", it means that theggplot()function is not accessible because the package that contains the function (ggplot2) was not loaded withlibrary(ggplot2). Thus you cannot use theggplot()function without theggplot2package being loaded first. - Warnings: When the red text is a warning, it will be prefaced with “Warning:” and R will try to explain why there’s a warning. Generally your code will still work, but with some caveats. For example, you will see in Chapter 12 if you create a scatterplot based on a dataset where one of the values is missing, you will see this warning:
Warning: Removed 1 rows containing missing values (geom_point). R will still produce the scatterplot with all the remaining values, but it is warning you that one of the points isn’t there. - Messages: When the red text doesn’t start with either “Error” or “Warning”, it’s just a friendly message. You’ll see these messages when you load R packages in the upcoming Subsection 11.6.2 or when you read data saved in spreadsheet files with the
read_csv()function as you’ll see in Chapter ??. These are helpful diagnostic messages and they don’t stop your code from working. Additionally, you’ll see these messages when you install packages too usinginstall.packages().
Important!
When you see red text in the console, don’t panic! Just check out what it could be.
Remember, when you see red text in the console, don’t panic. It doesn’t necessarily mean anything is wrong. Rather:
- If the text starts with “Error”, figure out what’s causing it. Think of errors as a red traffic light: something is wrong!
- If the text starts with “Warning”, figure out if it’s something to worry about. For instance, if you get a warning about missing values in a scatterplot and you know there are missing values, you’re fine. If that’s surprising, look at your data and see what’s missing. Think of warnings as a yellow traffic light: everything is working fine, but watch out/pay attention.
- Otherwise the text is just a message. Read it, wave back at R, and thank it for talking to you. Think of messages as a green traffic light: everything is working fine.
11.5.2 Tips on learning to code
Learning to code/program is very much like learning a foreign language, it can be very daunting and frustrating at first. Such frustrations are very common and it is very normal to feel discouraged as you learn. However just as with learning a foreign language, if you put in the effort and are not afraid to make mistakes, anybody can learn.
Here are a few useful tips to keep in mind as you learn to program:
- Remember that computers are not actually that smart: You may think your computer or smartphone are “smart,” but really people spent a lot of time and energy designing them to appear “smart.” Rather you have to tell a computer everything it needs to do. Furthermore the instructions you give your computer can’t have any mistakes in them, nor can they be ambiguous in any way.
- Take the “copy, paste, and tweak” approach: Especially when learning your first programming language, it is often much easier to taking existing code that you know works and modify it to suit your ends, rather than trying to write new code from scratch. We call this the copy, paste, and tweak approach. So early on, we suggest not trying to write code from memory, but rather take existing examples we have provided you, then copy, paste, and tweak them to suit your goals. Don’t be afraid to play around!
- The best way to learn to code is by doing: Rather than learning to code for its own sake, we feel that learning to code goes much smoother when you have a goal in mind or when you are working on a particular project, like analyzing data that you are interested in.
- Practice is key: Just as the only method to improving your foreign language skills is through practice, practice, and practice; so also the only method to improving your coding is through practice, practice, and practice. Don’t worry however; we’ll give you plenty of opportunities to do so!
11.6 What are R packages?
Another point of confusion with many new R users is the idea of an R package. R packages extend the functionality of R by providing additional functions, data, and documentation. They are written by a world-wide community of R users and can be downloaded for free from the internet. For example, among the many packages we will use in this book are the ggplot2 package for data visualization which we will cover later (or you can check here) or the dplyr package for data wrangling (again, we will cover later, but check this if you want to know more).
A good analogy for R packages is they are like apps you can download onto a mobile phone:
| R: A new phone | R Packages: Apps you can download |
|---|---|
 |
 |
So R is like a new mobile phone: while it has a certain amount of features when you use it for the first time, it doesn’t have everything. R packages are like the apps you can download onto your phone from Apple’s App Store or Android’s Google Play.
Let’s continue this analogy by considering the Instagram app for editing and sharing pictures. Say you have purchased a new phone and you would like to share a recent photo you have taken on Instagram. You need to:
- Install the app: Since your phone is new and does not include the Instagram app, you need to download the app from either the App Store or Google Play. You do this once and you’re set. You might do this again in the future any time there is an update to the app.
- Open the app: After you’ve installed Instagram, you need to open the app.
Once Instagram is open on your phone, you can then proceed to share your photo with your friends and family. The process is very similar for using an R package. You need to:
- Install the package: This is like installing an app on your phone. Most packages are not installed by default when you install R and RStudio. Thus if you want to use a package for the first time, you need to install it first. Once you’ve installed a package, you likely won’t install it again unless you want to update it to a newer version.
- “Load” the package: “Loading” a package is like opening an app on your phone. Packages are not “loaded” by default when you start RStudio on your computer; you need to “load” each package you want to use every time you start RStudio.
Let’s now show you how to perform these two steps for the ggplot2 package for data visualization.
11.6.1 Package installation
For the most part, in Posit Cloud, I will pre-install the packages you are going to need to use. But just in case you also want to work on your own machine, or install your own packages, here I explain that a bit more. There are two ways to install an R package. For example, to install the ggplot2 package:
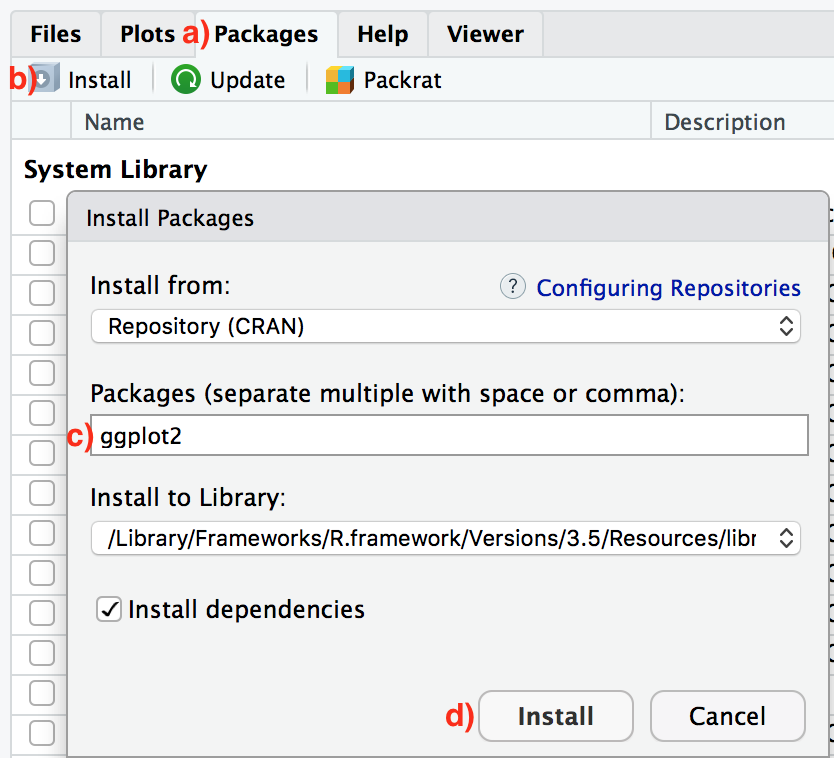
- Easy way: In the Files pane of RStudio/Posit Cloud:
- Click on the “Packages” tab
- Click on “Install”
- Type the name of the package under “Packages (separate multiple with space or comma):” In this case, type
ggplot2 - Click “Install”
- Slightly harder way: An alternative but slightly less convenient way to install a package is by typing
install.packages("ggplot2")in the Console pane of RStudio and hitting enter. Note you must include the quotation marks.
Much like an app on your phone, you only have to install a package once. However, if you want to update an already installed package to a newer verions, you need to re-install it by repeating the above steps.
Learning check
dplyr, and knitr packages. This will install the earlier mentioned dplyr package, and the knitr package for writing reports in R.
11.6.2 Package loading
Recall that after you’ve installed a package, you need to “load” it, in other words open it. We do this by using the library() command. For example, to load the ggplot2 package, run the following code in the Console pane. What do we mean by “run the following code”? Either type or copy & paste the following code into the Console pane and then hit the enter key.
If after running the above code, a blinking cursor returns next to the > “prompt” sign, it means you were successful and the ggplot2 package is now loaded and ready to use. If however, you get a red “error message” that reads…
Error in library(ggplot2) : there is no package called ‘ggplot2’… it means that you didn’t successfully install it. In that case, go back to the previous subsection “Package installation” and install it.
Learning check
dplyr, and knitr packages as well by repeating the above steps.
11.6.3 Package use
One extremely common mistake new R users make when wanting to use particular packages is that they forget to “load” them first by using the library() command we just saw. Remember: you have to load each package you want to use every time you start RStudio. If you don’t first “load” a package, but attempt to use one of its features, you’ll see an error message similar to:
Error: could not find functionR is telling you that you are trying to use a function in a package that has not yet been “loaded.” Almost all new users forget do this when starting out, and it is a little annoying to get used to. However, you’ll remember with pratice.
11.7 Hands-on exercise!
11.7.1 Explore your first dataset: economic mobility in the US
Let’s put everything we’ve learned so far into practice and start exploring some real data! These “spreadsheet”-type datasets are called data frames in R; we will focus on working with data saved as data frames throughout this course.
Step 1: Load all the packages needed for this exercise (assuming you’ve already installed them).
11.7.2 Economic mobility data
The Opportunity Atlas is a freely available interactive mapping tool that traces the roots of outcomes such as poverty and incarceration back to the neighborhoods in which children grew up. The atlas dataset we loaded has the underlying data to describe equality of opportunity across the 73,278 different neighborhoods in the United States.
Let’s unpack these data a bit more!
11.7.3 atlas data frame
We will begin by exploring the atlas data frame we just loaded to get an idea of its structure. Run the following code in your console (either by typing it or cutting & pasting it): it loads the atlas dataset into your Console. Note depending on the size of your monitor, the output may vary slightly.
## # A tibble: 73,278 × 62
## tract county state cz czname hhinc…¹ mean_…² frac_…³ frac_…⁴ forei…⁵ med_h…⁶ med_h…⁷ popde…⁸ poor_…⁹ poor_…˟ poor_…˟ share…˟ share…˟
## <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 20100 1 1 11101 Montgome… 68639. 26.2 0.254 0.156 0.00995 66000 27375 196. 0.105 0.127 0.0989 0.119 0.0230
## 2 20200 1 1 11101 Montgome… 57243. 24.8 0.267 0.147 0.0163 41107 19000 566. 0.148 0.227 0.198 0.565 0.0346
## 3 20300 1 1 11101 Montgome… 75648. 25.3 0.164 0.224 0.0271 51250 29419 624. 0.0804 0.0766 0.114 0.198 0.0258
## 4 20400 1 1 11101 Montgome… 74852. 23.0 0.253 0.230 0.0151 52704 37891 714. 0.0632 0.0455 0.0679 0.0467 0.0194
## 5 20500 1 1 11101 Montgome… 96175. 26.2 0.375 0.321 0.0465 52463 41516 530. 0.0596 0.0368 0.0547 0.140 0.0330
## 6 20600 1 1 11101 Montgome… 68096. 21.6 0.239 0.161 0.0250 63750 29000 408. 0.105 0.152 0.178 0.212 0.0480
## 7 20700 1 1 11101 Montgome… 65182. 23.2 0.0691 0.117 0.0199 45234 26895 129. 0.166 0.110 0.177 0.156 0.0339
## 8 20801 1 1 11101 Montgome… 76874. 30.3 0.283 0.188 0.00245 74603 30957. 17.5 0.0797 0.0877 0.108 0.0951 0.0185
## 9 20802 1 1 11101 Montgome… 77310. 30.7 0.195 0.189 0.00691 61242 31137. 38.2 0.116 0.0844 0.102 0.136 0.0152
## 10 20900 1 1 11101 Montgome… 66234. 36.4 0.128 0.0893 0.00967 44591 18430 15.8 0.0991 0.138 0.246 0.122 0.0169
## # … with 73,268 more rows, 44 more variables: share_asian2010 <dbl>, share_black2000 <dbl>, share_white2000 <dbl>, share_hisp2000 <dbl>,
## # share_asian2000 <dbl>, gsmn_math_g3_2013 <dbl>, rent_twobed2015 <dbl>, singleparent_share2010 <dbl>, singleparent_share1990 <dbl>,
## # singleparent_share2000 <dbl>, traveltime15_2010 <dbl>, emp2000 <dbl>, mail_return_rate2010 <dbl>, ln_wage_growth_hs_grad <dbl>,
## # jobs_total_5mi_2015 <dbl>, jobs_highpay_5mi_2015 <dbl>, nonwhite_share2010 <dbl>, popdensity2010 <dbl>,
## # ann_avg_job_growth_2004_2013 <dbl>, job_density_2013 <dbl>, kfr_natam_p25 <dbl>, kfr_natam_p75 <dbl>, kfr_natam_p100 <dbl>,
## # kfr_asian_p25 <dbl>, kfr_asian_p75 <dbl>, kfr_asian_p100 <dbl>, kfr_black_p25 <dbl>, kfr_black_p75 <dbl>, kfr_black_p100 <dbl>,
## # kfr_hisp_p25 <dbl>, kfr_hisp_p75 <dbl>, kfr_hisp_p100 <dbl>, kfr_pooled_p25 <dbl>, kfr_pooled_p75 <dbl>, kfr_pooled_p100 <dbl>, …Let’s unpack this output:
A tibble: 73,278 x 62: Atibbleis a kind of data frame used in R. This particular data frame has73,278rows (one for each neighborhood)62columns corresponding to 62 variables describing each observation (e.g. neighborhood in this case)
tract county state cz czname hhinc_mean2000 mean_commutetime2000 ...are different columns, in other words variables, of this data frame.- We then have the first 10 rows of observations corresponding to 10 neighborhoods.
... with 73,268 more rows, and 52 more variables:indicating to us that 73,268 more rows of data and 52 more variables could not fit in this screen.
Unfortunately, this output does not allow us to explore the data very well. Let’s look at different tools to explore data frames.
11.7.4 Exploring data frames
Among the many ways of getting a feel for the data contained in a data frame such as atlas, we present three functions that take as their “argument”, in other words their input, the data frame in question. We also include a fourth method for exploring one particular column of a data frame:
- Using the
View()function built for use in RStudio. We will use this the most. - Using the
glimpse()function, which is included in thedplyrpackage. - Using the
$operator to view a single variable in a data frame.
1. View():
Run View(atlas) in your Console in RStudio, either by typing it or cutting & pasting it into the Console pane, and explore this data frame in the resulting pop-up viewer. You should get into the habit of always Viewing any data frames that come your way. Note the capital “V” in View. R is case-sensitive so you’ll receive an error is you run view(atlas) instead of View(atlas).
Learning check
(LC2.3) What does any ONE row in this atlas dataset refer to?
- A. Data on an neighborhood
- B. Data on a state
- C. Data on an person
- D. Data on multiple neighborhood
By running View(atlas), we see the different variables listed in the columns and we see that there are different types of variables. Some of the variables like poor_share2010, hhinc_mean2000, and share_hisp2010 are what we will call quantitative variables. These variables are numerical in nature. Other variables, like tract are categorical: they are just names (even if they have numbers). For example tract represents a Tract FIPS Code, that is, a 6-digit code assigned by the census folks to each neighborhood in 2010.
Note that if you look in the leftmost column of the View(atlas) output, you will see a column of numbers. These are the row numbers of the dataset. If you glance across a row with the same number, say row 5, you can get an idea of what each row corresponds to.
2. glimpse():
The second way to explore a data frame is using the glimpse() function included in the dplyr package. Thus, you can only use the glimpse() function after you’ve loaded the dplyr package. This function provides us with an alternative method for exploring a data frame:
## Rows: 73,278
## Columns: 62
## $ tract <dbl> 20100, 20200, 20300, 20400, 20500, 20600, 20700, 20801, 20802, 20900, 21000, 21100, 10100, 10200, 1030…
## $ county <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, …
## $ state <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
## $ cz <dbl> 11101, 11101, 11101, 11101, 11101, 11101, 11101, 11101, 11101, 11101, 11101, 11101, 11001, 11001, 1100…
## $ czname <chr> "Montgomery", "Montgomery", "Montgomery", "Montgomery", "Montgomery", "Montgomery", "Montgomery", "Mon…
## $ hhinc_mean2000 <dbl> 68639, 57243, 75648, 74852, 96175, 68096, 65182, 76874, 77310, 66234, 58866, 52435, 58306, 56810, 7095…
## $ mean_commutetime2000 <dbl> 26.2, 24.8, 25.3, 23.0, 26.2, 21.6, 23.2, 30.3, 30.7, 36.4, 41.7, 28.5, 40.2, 31.8, 30.0, 32.8, 24.3, …
## $ frac_coll_plus2010 <dbl> 0.2544, 0.2672, 0.1642, 0.2527, 0.3751, 0.2394, 0.0691, 0.2826, 0.1949, 0.1278, 0.1136, 0.0937, 0.1012…
## $ frac_coll_plus2000 <dbl> 0.1565, 0.1469, 0.2244, 0.2305, 0.3212, 0.1607, 0.1169, 0.1882, 0.1895, 0.0893, 0.0829, 0.0842, 0.0872…
## $ foreign_share2010 <dbl> 0.00995, 0.01634, 0.02710, 0.01508, 0.04649, 0.02499, 0.01989, 0.00245, 0.00691, 0.00967, 0.00589, 0.0…
## $ med_hhinc2016 <dbl> 66000, 41107, 51250, 52704, 52463, 63750, 45234, 74603, 61242, 44591, 49567, 40801, 45667, 33333, 4744…
## $ med_hhinc1990 <dbl> 27375, 19000, 29419, 37891, 41516, 29000, 26895, 30957, 31137, 18430, 17188, 17191, 19488, 20821, 2172…
## $ popdensity2000 <dbl> 195.72, 566.38, 624.20, 713.80, 529.93, 408.37, 129.42, 17.49, 38.19, 15.81, 6.92, 6.24, 4.28, 11.88, …
## $ poor_share2010 <dbl> 0.1050, 0.1476, 0.0804, 0.0632, 0.0596, 0.1052, 0.1663, 0.0797, 0.1161, 0.0991, 0.2023, 0.1801, 0.0315…
## $ poor_share2000 <dbl> 0.1268, 0.2271, 0.0766, 0.0455, 0.0368, 0.1522, 0.1100, 0.0877, 0.0844, 0.1384, 0.1759, 0.2260, 0.1605…
## $ poor_share1990 <dbl> 0.0989, 0.1983, 0.1140, 0.0679, 0.0547, 0.1781, 0.1773, 0.1081, 0.1015, 0.2456, 0.2932, 0.2788, 0.2675…
## $ share_black2010 <dbl> 0.11925, 0.56498, 0.19804, 0.04674, 0.13970, 0.21156, 0.15635, 0.09510, 0.13608, 0.12211, 0.21113, 0.5…
## $ share_hisp2010 <dbl> 0.02301, 0.03456, 0.02579, 0.01938, 0.03297, 0.04798, 0.03390, 0.01850, 0.01524, 0.01692, 0.01348, 0.0…
## $ share_asian2010 <dbl> 0.004707, 0.002304, 0.004744, 0.003648, 0.026032, 0.001636, 0.003459, 0.004544, 0.005196, 0.002082, 0.…
## $ share_black2000 <dbl> 0.07548, 0.62209, 0.14915, 0.02590, 0.06010, 0.16903, 0.09690, 0.13313, 0.13134, 0.13783, 0.26896, 0.5…
## $ share_white2000 <dbl> 0.897, 0.355, 0.820, 0.938, 0.897, 0.799, 0.868, 0.840, 0.842, 0.825, 0.710, 0.395, 0.720, 0.875, 0.77…
## $ share_hisp2000 <dbl> 0.00625, 0.00846, 0.01647, 0.02217, 0.01573, 0.01954, 0.01759, 0.01049, 0.01005, 0.01750, 0.00784, 0.0…
## $ share_asian2000 <dbl> 0.003644, 0.003171, 0.003893, 0.007288, 0.010596, 0.001480, 0.003793, 0.002242, 0.002280, 0.002160, 0.…
## $ gsmn_math_g3_2013 <dbl> 2.76, 2.76, 2.76, 2.76, 2.76, 2.76, 2.76, 2.76, 2.76, 2.76, 2.76, 2.76, 2.79, 2.79, 2.79, 2.79, 2.79, …
## $ rent_twobed2015 <dbl> NA, 907, 583, 713, 923, 765, 645, 532, 671, 710, NA, NA, NA, 619, NA, 880, 636, 523, 937, 1139, 936, 9…
## $ singleparent_share2010 <dbl> 0.1139, 0.4885, 0.2281, 0.2275, 0.2597, 0.3164, 0.5796, 0.1630, 0.2583, 0.2648, 0.2953, 0.3711, 0.0471…
## $ singleparent_share1990 <dbl> 0.1812, 0.3525, 0.1259, 0.1268, 0.0744, 0.2380, 0.2438, 0.1456, 0.1373, 0.1893, 0.2239, 0.2891, 0.2651…
## $ singleparent_share2000 <dbl> 0.251, 0.393, 0.245, 0.191, 0.168, 0.289, 0.393, 0.204, 0.200, 0.238, 0.262, 0.399, 0.256, 0.241, 0.23…
## $ traveltime15_2010 <dbl> 0.2730, 0.1520, 0.2055, 0.3507, 0.2505, 0.3416, 0.1270, 0.2324, 0.1796, 0.0618, 0.1025, 0.1515, 0.0605…
## $ emp2000 <dbl> 0.567, 0.493, 0.579, 0.597, 0.661, 0.643, 0.670, 0.645, 0.645, 0.547, 0.512, 0.549, 0.515, 0.588, 0.60…
## $ mail_return_rate2010 <dbl> 83.5, 81.3, 79.5, 83.5, 77.3, 82.8, 83.2, 85.5, 85.4, 83.0, 86.7, 81.2, 73.6, 78.0, 81.2, 79.2, 81.8, …
## $ ln_wage_growth_hs_grad <dbl> 0.03823, 0.08931, -0.17774, -0.07231, -0.09614, -0.04856, -0.18548, NA, NA, 0.03584, -0.30637, 0.14551…
## $ jobs_total_5mi_2015 <dbl> 10109, 9948, 10387, 12933, 12933, 9193, 11578, 1567, 2615, 279, 212, 151, 133, 1199, 641, 1073, 4838, …
## $ jobs_highpay_5mi_2015 <dbl> 3396, 3328, 3230, 3635, 3635, 3052, 3389, 989, 1176, 106, 126, 26, 47, 540, 189, 518, 1632, 1632, 503,…
## $ nonwhite_share2010 <dbl> 0.1627, 0.6111, 0.2476, 0.0812, 0.2162, 0.2715, 0.2065, 0.1366, 0.1712, 0.1567, 0.2370, 0.5681, 0.2489…
## $ popdensity2010 <dbl> 504.8, 1682.2, 1633.4, 1780.0, 2446.3, 1184.4, 334.1, 64.2, 141.6, 50.2, 19.4, 18.0, 10.1, 33.9, 59.0,…
## $ ann_avg_job_growth_2004_2013 <dbl> -0.006769, -0.004253, 0.014218, -0.019841, 0.018627, -0.051588, 0.005518, -0.039299, 0.008160, 0.00154…
## $ job_density_2013 <dbl> 92.133, 971.318, 340.920, 207.386, 800.273, 336.778, 141.123, 3.501, 14.049, 2.566, 1.446, 0.970, 0.33…
## $ kfr_natam_p25 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ kfr_natam_p75 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ kfr_natam_p100 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ kfr_asian_p25 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ kfr_asian_p75 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ kfr_asian_p100 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ kfr_black_p25 <dbl> 26819, 18138, 20515, 12883, 26594, 19108, 17269, 10235, 23543, 24216, 25893, 22547, 22450, NA, 23323, …
## $ kfr_black_p75 <dbl> 45926, 33842, 34133, 40334, 42575, 26062, 32101, 19439, 42654, 34438, 44593, 30808, 45014, NA, 36403, …
## $ kfr_black_p100 <dbl> 84690, 60512, 56516, 105250, 72565, 35737, 56359, 32350, 80709, 50392, 82002, 42879, 94068, NA, 58334,…
## $ kfr_hisp_p25 <dbl> NA, NA, NA, 26363, 17234, NA, NA, NA, 32946, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 70899, 29314,…
## $ kfr_hisp_p75 <dbl> NA, NA, NA, 67532, 44642, NA, NA, NA, 65539, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 54937, 48182,…
## $ kfr_hisp_p100 <dbl> NA, NA, NA, NA, 93976, NA, NA, NA, 147274, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 40977, 77965, N…
## $ kfr_pooled_p25 <dbl> 27621, 22303, 28215, 33331, 34633, 23583, 27612, 22428, 27915, 26084, 27221, 24694, 29388, 31710, 2990…
## $ kfr_pooled_p75 <dbl> 51531, 46650, 50754, 52337, 57007, 47735, 42969, 51959, 51986, 54122, 61254, 42912, 57854, 48092, 5425…
## $ kfr_pooled_p100 <dbl> 78922, 74225, 76055, 72586, 81792, 75188, 58086, 88557, 79622, 88273, 107923, 61531, 92696, 64860, 822…
## $ kfr_white_p25 <dbl> 30328, 42189, 33670, 34181, 39540, 27835, 32270, 29066, 31379, 29027, 30816, 33295, 35404, 34276, 3830…
## $ kfr_white_p75 <dbl> 50820, 54239, 51579, 52848, 58699, 51198, 44085, 54860, 53174, 57420, 64735, 50792, 60553, 47399, 5809…
## $ kfr_white_p100 <dbl> 75126, 66646, 71991, 74330, 80415, 80144, 56134, 88027, 79508, 95584, 117001, 70607, 92027, 61231, 808…
## $ count_pooled <dbl> 519, 530, 960, 1123, 1867, 994, 772, 632, 2114, 1373, 760, 851, 1090, 705, 1716, 1265, 925, 1297, 1728…
## $ count_white <dbl> 457, 173, 774, 1033, 1626, 756, 630, 523, 1756, 1125, 478, 289, 724, 591, 1239, 1138, 799, 458, 1582, …
## $ count_black <dbl> 42, 336, 151, 40, 137, 198, 111, 89, 290, 211, 262, 552, 319, 83, 433, 88, 94, 787, 85, 172, 48, 181, …
## $ count_asian <dbl> 3, 1, 1, 6, 13, 2, 1, 1, 5, 0, 0, 0, 0, 3, 1, 0, 8, 3, 10, 9, 5, 17, 10, 2, 3, 3, 2, 4, 8, 3, 15, 13, …
## $ count_hisp <dbl> 4, 5, 21, 37, 39, 19, 14, 9, 29, 17, 7, 3, 18, 8, 21, 14, 11, 18, 23, 31, 24, 52, 20, 23, 30, 36, 20, …
## $ count_natam <dbl> 6, 1, 2, 0, 8, 2, 9, 1, 5, 4, 8, 3, 20, 8, 9, 3, 6, 3, 3, 5, 1, 4, 1, 9, 11, 12, 6, 11, 3, 2, 1, 0, 3,…We see that glimpse() will give you the first few entries of each variable in a row after the variable. In addition, the data type of the variable is given immediately after each variable’s name inside < >. Here, int and dbl refer to “integer” and “double”, which are computer coding terminology for quantitative/numerical variables. In contrast, chr refers to “character”, which is computer terminology for text data. Text data, such as the czname (the name of the metro area), are categorical variables.
3. $ operator
Lastly, the $ operator allows us to explore a single variable within a data frame. For example, run the following in your console
We used the $ operator to extract only the tract variable and return it as a vector of length 73,278. We will only be occasionally exploring data frames using this operator, instead favoring the View() and glimpse() functions.
11.8 Conclusion
We’ve given you what we feel are the most essential concepts to know before you can start exploring data in R. There is much more to explore in R but this is a great place to get started!
11.8.1 Additional resources
If you want to dive more and feel you could benefit from a more detailed introduction, check this short book: Getting used to R, RStudio, and R Markdown short book.
It has screencast recordings that you can follow along and pause as you learn. Furthermore, there is an introduction to R Markdown, a tool used for reproducible research in R. We will see more about that in the next class.
If you truly insist on getting more information, you can check this link explaining some of the basics: https://rstudio-education.github.io/hopr/basics.html ;but again, this is not required or expected.↩︎